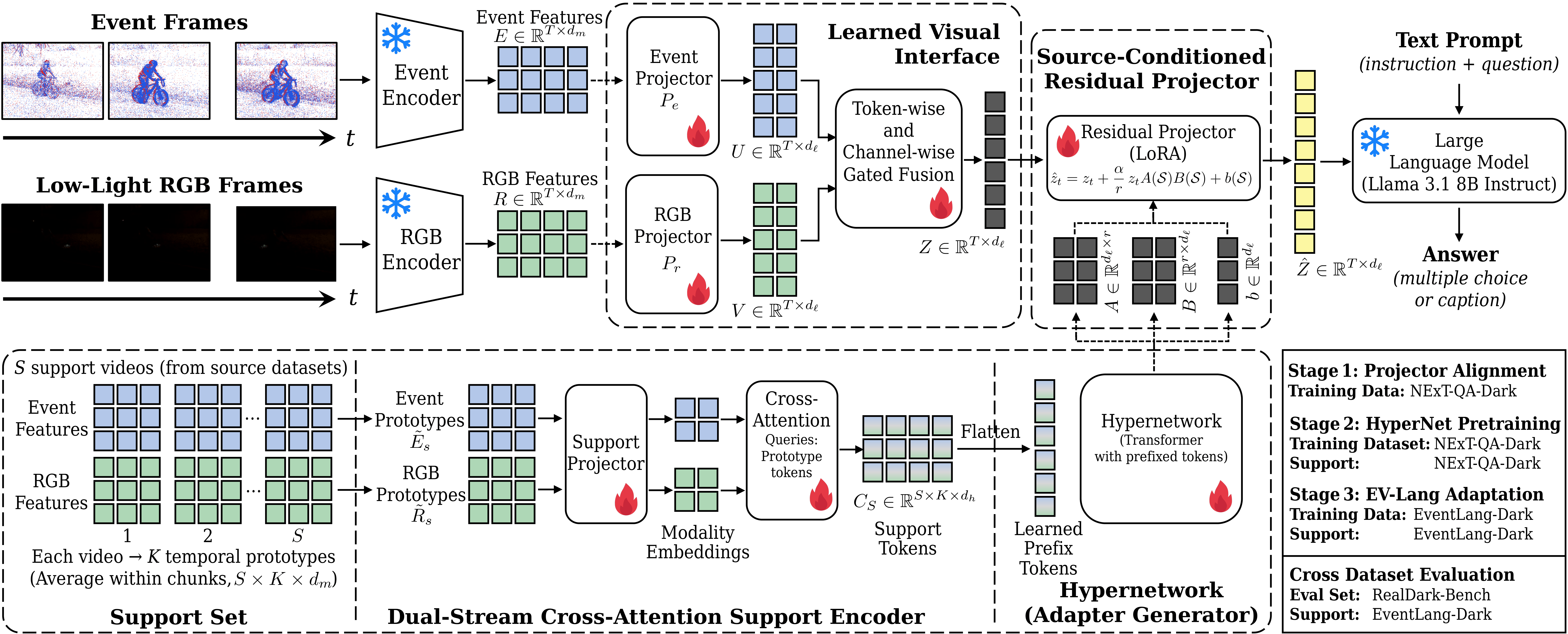
Method
Overview of the LITE-Event framework. Frozen encoders extract initial features from low-light RGB video and temporal event streams, which are subsequently mapped into the embedding space of a large language model using modality-specific projectors. A learned gating mechanism fuses these distinct inputs into unified visual tokens, which are dynamically refined at inference time by a hypernetwork-driven, support-conditioned residual projector. Finally, these adapted representations are aligned with the user's text query and processed by an instruction-tuned LLM, enabling robust reasoning and accurate answer generation under challenging low-light conditions.